
AIでデータ圧縮
基幹理工学部 情報通信学科 甲藤 二郎
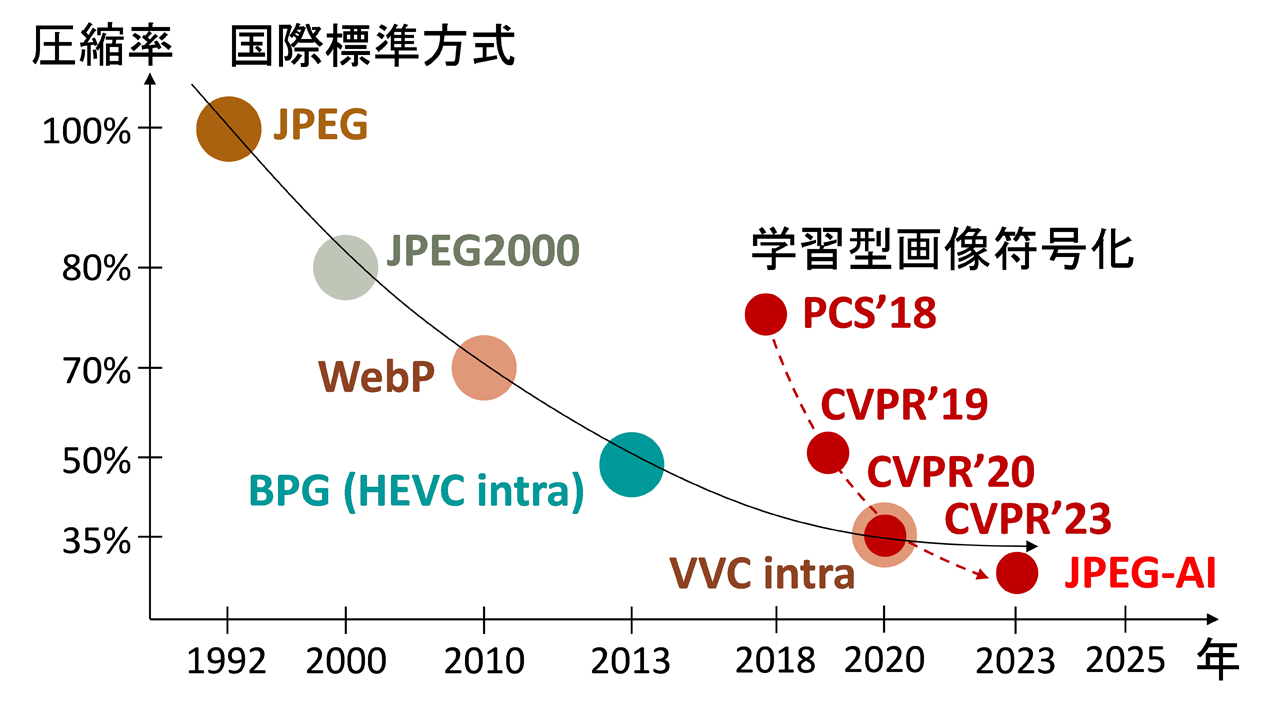 静止画像の圧縮に関する国際標準方式と学習型符号化の発展の歴史
静止画像の圧縮に関する国際標準方式と学習型符号化の発展の歴史皆さんは、今日スマートフォンで見た動画は、どうやって手元に届くのか、考えたことはあるでしょうか? 現在、インターネットを流れるトラヒックの8割以上が動画であり(Cisco VNI)、クラウドや通信技術の貢献もありますが、それらが問題なく届くのは「データ圧縮」という技術のおかげです。
データ圧縮とは、情報を小さく詰め込む技術です。たとえば「あああああああ」という文字列は「あ×7」と書き直せます。動画の場合も、隣り合うフレームは似ているので、差分だけを送ることで大幅にデータ量を減らせます。この考え方は50年以上前から研究されており、現在私たちが日常的に使っているYouTubeやZoomでも、こうした古典的な圧縮技術が使われています。JPEGやMPEGという言葉を聞いたことがあるかもしれませんが、これらは画像・動画圧縮に関わる国際標準方式です。
では、AIはデータ圧縮にどう関わるのでしょうか。
近年、深層学習を使った「学習型符号化」という新しいアプローチが発展しています。従来の圧縮技術は、人間が計算ルールを設計していましたが、学習型符号化では、AIが大量の画像や動画を学習し、「どこを残してどこを省くか」を自動的に見つけ出します。人間には思いつかなかったような、賢い情報の削り方をAIが発見します。
さらに面白いのは、AIは単に「省く」だけでなく、省いた部分を「補完する」こともできます。画像生成AIが写真を描けるように、受け取った側のAIが欠けた情報を自然に補い、人間の目に見える映像として再現します。これは従来の圧縮では考えていなかった発想です。
図には、静止画像の圧縮に関する国際標準方式と学習型符号化の発展の歴史を示します。縦軸は、JPEGを100%とした場合の圧縮率を示し、この値が小さいほど優れた画像圧縮方式であることを示します。国際標準方式は、1992年のJPEG以来、30年以上をかけて進化して来ました。これに対し、学習型符号化は、深層学習の研究開発が活発化する中で2017年頃に開始され、国際標準を明確な目標として急速に進展し、わずか数年で国際標準を凌ぐ圧縮性能を実現しました。これは逆に国際標準化活動を動かし、学習型符号化に基づく国際標準方式として、2025年にはJPEG-AIが国際標準として策定されました。
さらに、学習型符号化の対象も、上記の静止画像だけではなく、動画像、音楽、三次元点群、三次元シーンへと拡がっています。三次元点群の圧縮は、自動運転などへの応用が期待されています。また、三次元シーンの圧縮は、AR/VRやデジタルツインなどへの応用が期待されています。さらに、深層学習との親和性を活かし、コンピュータビジョンや大規模言語モデルとの親和性も高く、圧縮領域のコンピュータビジョン、大規模言語モデルを活用したデータ圧縮、意味情報を取り出すセマンティック通信、などへの展開が活発に検討されています。
もちろん課題もあります。学習型符号化はまだ計算コストが高いとされ、リアルタイム通信に使うには工夫が必要です。また、GPUの世代違いによって復号に失敗するという、学習型符号化特有の問題(クロスプラットフォーム問題)もあります。こうした問題を一つ一つ解決して行くことが、実用化に向けた検討課題です。
目には見えない技術のため、データ圧縮は地味に聞こえるかもしれませんが、インターネットの根幹を支える技術です。そしてそこにAIが加わることで、新しい情報通信の世界の開拓が期待されています。