生物の研究と聞いて思い浮かべるのはどのような光景でしょうか?おそらく白衣を身にまとった研究者が試験管を片手に薬品を混ぜ合わせている姿を想像するのではないでしょうか。ところが現代の生物学では、こういった実験による研究だけでなく、コンピュータによる解析が非常に重要な役割を果たしているのです。
ヒトゲノム解読成功の裏にはコンピュータあり
一例をあげましょう。生命の設計図であるゲノムは4種類の塩基が鎖状につながった物質です。そのため、4種類のアルファベットから構成される文章とみなすことができます。人のゲノムの長さは30億塩基対です。つまり、30億文字からなる文章の中に人を創るために必要な秘密が隠されているのです。この秘密を解き明かすのは容易ではありません。研究者たちはまず、辞書を作ることから始めました。一人分のヒトゲノムがどのような文章なのか、約10年間かけて読み解いたのです。これが1990年から始まったヒトゲノム計画です。実はこのヒトゲノム計画では、コンピュータが非常に重要な役割を果たしました。DNAからまとまって読み取れる塩基の並びは長くても1000塩基程度です。そのため、長い文章からバラバラに読み取られた膨大な量の短文を、短文間の“のりしろ”を考慮しながらつなぎ合わせ、元の文章を復元する必要があったのです(図1)。
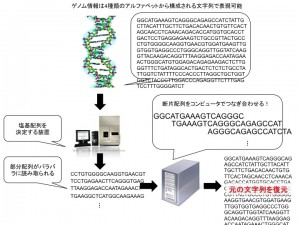
図1
このような作業は人の手では到底完遂不可能です。ヒトゲノム計画ではコンピュータを巧みに利用してこの問題を解き、ゲノムの辞書を作り上げることができたのです。
ゲノムビックデータ
ゲノム研究において、コンピュータの重要性は劇的に増しています。まず、図2をご覧ください。
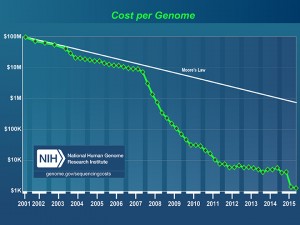
図2
こちらは、アメリカ国立衛生研究所(National Institute of Health)が試算した一人分のヒトゲノムを読みとるのに必要な金額を示したグラフです。縦軸がコスト、横軸が年を示しています。2000年代後半から急激にコストが下落しているのがわかると思います。前述のヒトゲノム計画には約3000億円が投入されましたが、現在では装置の性能向上によって、なんと一人分のゲノムを10万円で読むことができるようになってしまったのです。これにより、世界中の研究機関で大量のゲノムデータが算出されるようになりました。このような状況になってしまうと、もはや一つ一つのデータを丁寧に人が見て解析というのは不可能です。大量のゲノムデータを超高速に処理して、生命現象に関わる情報を自動的に抽出する必要があるのです。さらに、ヒトゲノムを取り扱う際には、セキュリティの問題にも十分注意を払わなければなりません。最新の研究では、暗号を使ってデータの中身を隠しながらゲノム情報を解析する手法の利用も検討されており、ここでもコンピュータが活躍をしています。
計算生物学
コンピュータの重要性はゲノム解析だけにとどまりません。生体内で働くタンパク質の立体構造を解析し、薬の候補になる化合物との結合度合を予測(あるいはシミュレーション)するのもコンピュータの役割です。その他にも、ここでは紹介しきれないほどたくさんの問題でコンピュータの利用が進んでいます。このように生物の実験を行わず、データの解析に特化した研究(あるいはその解析に役立つ技術を開発する研究)を総称して「計算生物学」(もしくは,バイオインフォマティクス)と呼びます。冒頭に述べましたとおり、計算生物学の重要性は生物を専門とする研究者の間でも広く認められるようになり、最近では実験も行いつつコンピュータによる解析も行うハイブリッドな研究者も増加しています。
生物学という、およそコンピュータとは縁遠く聞こえる分野においても主役級の役割を果たしているコンピュータについて、ぜひ学んでみませんか?