学校のログイン、SNSのログイン、ネット通販のログイン、ネット銀行のログイン、、、あなたはいくつパスワードを覚えていますか?もっというと、覚えさせられていますか?
パスワードは、あなたがサービスに登録した本人であることを示すための重要な情報です。他人に類推されてなりすまされないように、長くて複雑なパスワードが望ましいですが、覚えるのに一苦労します。なので、複雑なパスワードを様々なサービスで使いまわしたくなりますが、これは危険です。どこかのサイトからIDパスワードが流出すると、そのリストが裏インターネットに出回ってしまいます。そしてこの情報で他のサイトのログインに使えないかを試そうとする人たちがいます。
アカウントをいちいち作ってパスワードを設定するのは大変だから、GoogleやFacebookやTwitterのアカウントで便利にログインしているよ、という人もいるでしょう(ソーシャルログインと呼ばれます)。確かに、これらのテックジャイアントはあなたのパスワードをしっかり守ろうとしてくれるでしょう。同時にあなたのこともよく知ろうとしています。あなたがこのアカウントを使ってどんなサービスに登録しているか。そのサービスをどの時間帯にどれだけ使っているか。そして自分の顧客の事業者に「こんなことに興味をもっているユーザがいますよ。あなたの製品を買うかもしれませんよ。この人に広告を出しませんか」と営業をしています。
ソーシャルログインは使わずに、ブラウザに覚えてもらっていたり、パスワード管理ツールを使っている人もいるかもしれません。このあたりが現実的な身の守り方のような気もしますが、ブラウザ提供企業、管理ツール提供企業(テックプロバイダーと総称します)に多くの情報をゆだねることになっていそうです。
これからも、自分でたくさんパスワードを覚えるか、テックジャイアントやテックプロバイダーに自分の情報をゆだねるかしかないのでしょうか。これに対して、早稲田大学ではパスワードに代わる新しい本人認証技術の研究と、それを多くの人につかってもらえるよう普及活動を行っています。
技術的には、パスワードに代わる本人認証手段として、「公開鍵暗号」や「ゼロ知識証明」を使った新しい認証手段を研究しています。パスワードは知られてしまったら本人になりすまされてしまう情報なのに、ログイン時に提示しないといけない、というのが大きな問題です。公開鍵暗号技術を使うと、相手に見せるのは公開鍵だけ。そして、ゼロ知識証明技術を使って、「私はその公開鍵に対応する秘密鍵を持っている」ということを証明して本人を認証することができます。ゼロ知識証明なので、この証明を何度実施しても秘密鍵に関して漏れる「知識」は「ゼロ」になり、安全であることが保証されます。この方式であれば同じ公開鍵を複数のサービスに登録しても秘密鍵が漏洩するリスクは少なくなります。でも同じ公開鍵だと、この人が他にどんなサービスに登録しているのか、追跡できてしまう問題が発生します。そこで、さらに「匿名認証技術」[1]を活用して、公開鍵さえも秘匿しつつ、必要なセキュリティ要件を満たす方式が構築できます。
制度的には、このようなゼロ知識証明や匿名認証技術を用いたアーキテクチャを多くのサービスで活用してもらえるよう、仲間を募り、オープンソースを開発し、標準化をすすめることに取り組んでいます。現在、この概念は World Wide Web Consortium (W3C) で Decentralized Identifiers (DID) [2] やVerifiable Credentials (VC) [3] として標準化策定がはじまっています。また、日本政府もTrusted Web推進協議会が2021年4月に発行したホワイトペーパー[4]でこの概念の可能性を議論しています。
身近な課題を解くためにどうすればよいか。そしてゆくゆくは「昔はたくさんのパスワードを覚えなくてはいけなくて大変だったんだよ」という昔話になるよう、今できることに取り組んでいます。
[1] 佐古・米澤・古川「セキュリティとプライバシを両立させる匿名認証技術について」
https://ci.nii.ac.jp/naid/110004734688
[2] W3C Decentralized Identifiers
https://www.w3.org/TR/did-core/
[3] W3C Verifiable Credentials Data Model
https://www.w3.org/TR/vc-data-model/
[4] Trusted Web ホワイトペーパーver 1.0
https://www.kantei.go.jp/jp/singi/digitalmarket/trusted_web/pdf/documents_210331-2.pdf
(URLはすべて2021年5月30日閲覧)
作成者アーカイブ: tokao
パスワード、いくつ覚えている?
フォトニクスの小さな巨人、半導体レーザ
電子物理システム学科 宇髙 勝之
私の専門の一つに半導体レーザがあります。私が半導体レーザに触れたきっかけは45余年前の学部3年に「電子物性工学」という科目を履修したことに遡ります。恩師の清水司教授の著になるその講義と同名の教科書は今でも私の書棚にあります。そこで材料とデバイスとの関係に大変興味を覚え、レーザについて初めて知りました。特に半導体レーザなるものの存在にある意味ショックを覚え、学部4年の卒論テーマで半導体レーザに関するものが有り、飛びつきました。その後半導体光集積回路なるものを知り、大学院でそれらを学び、現在に至っています。なぜ半導体レーザにショックを覚えたかですが、半導体〜シリコン〜トランジスタ〜LSIと短絡的な知識しか無かった当時、ヒ化ガリウム(GaAs)という耳慣れない半導体からレーザ光が発すると言うことが新鮮な驚きでした。1970年代当時まだ大変貴重な半導体レーザですが、修士の先輩との研究用に購入された現物を見ても肉眼では見えず、実体顕微鏡を覗いてやっと見えたその大きさはまさに砂粒ほどで黒い色でしたが、共振器となる劈開による結晶面が見る角度によって光を反射してきらりとしていました。またレーザ光は輝く光線というイメージも覆りました。用いた半導体レーザは近赤外光を発するものでしたので光は肉眼では見えません。ややがっかりしましたが、確かに光が出ていることは光検出器で分かりましたし、むしろ見えないことに隠れた存在感を感じ、卒論研究が進むにつれて段々とフォトニクス(または光エレクトロニクスとも呼ばれる)の小さな巨人、半導体レーザの偉大さに気付きました。
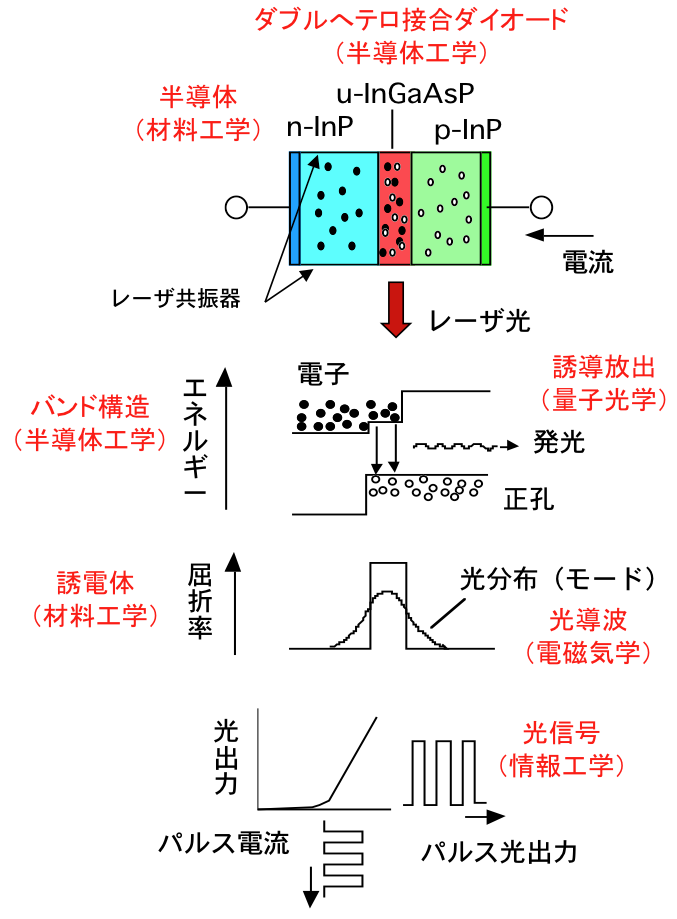
図1 半導体レーザの電流と光
前置きが長くなりましたが、半導体レーザは文字通り半導体材料によりダイオードが形成され、順方向電流を流すことによりレーザ光を発する光デバイスです。その大きさは砂粒ほどと呼ばれるように1ミリ角以下ですが光出力は数mW以上あり、十分100km程度の光ファイバ伝送が可能であり、さらにレーザポインタ、光ディスク、レーザプリンタ、光学式マウス、レーザ加工など応用は枚挙に暇がありません。
半導体レーザをフォトニクス分野での小さな巨人と呼ぶ理由は、小型に加えて低消費電力、群を抜く高効率であることから産業的にその応用が広いこと、そしてフォトニクスに関する重要な学術的要素が満載だからです。半導体レーザを学べばフォトニクスのかなりの部分を学んだと言っても過言で無いと思います。まず半導体の誘電体としての性質を学ぶことになります。誘電体は材料を構成する原子を取り巻く電子雲が入射光に応答して偏移する分極を発生させる材料ですが、電磁気学で学ぶ入射電界に対する応答係数である電気感受率は複素数で表され、実部はいわゆる屈折率、虚部は吸収係数に関係します。次にその屈折率を用いて光導波路を学びます。光導波路は光を効果的に導いたり操作する上で不可欠な要素です。良く知られている光導波路は、高度情報ネットワークの伝送路としてワイヤレスと並んで支えている光ファイバですが、半導体レーザも効率的に光を発生させたり、低損失で光ファイバと光接続させるために導波路構造が設けられています。次に電子工学または半導体工学として半導体の性質を学びます。不純物導入によるp型及びn型半導体をダブルヘテロ接合させてダイオードを形成し、電流を流して電子と正孔を注入し、それらの再結合で光が発生します。電流を流す仕組みは回路理論や電子回路で学びますが、その発光現象は前述の電気感受率の虚部と関係し、吸収係数の符号が反転して光増幅の概念に対応します。そしてその増幅される発光現象は誘導放出と呼ばれ、量子光学にも通じ、発生した光の振る舞いについて光学を学びます。すなわち光共振器により誘導放出光が定在波を形成し、位相が揃ったコヒーレントな波動であるレーザ光が回折理論に沿って半導体レーザから放出されます。また半導体工学や共振器形成に関しては結晶工学や半導体プロセスの知識も必要です。そして、放出したレーザ光を応用するために、光ファイバ通信やネットワークシステム、光機器、情報工学、さらに社会科学、科学技術産業論など学ぶことが沢山あります。量子通信、量子コンピューティング、人工知能などもフォトニクスと大きな関係があります。
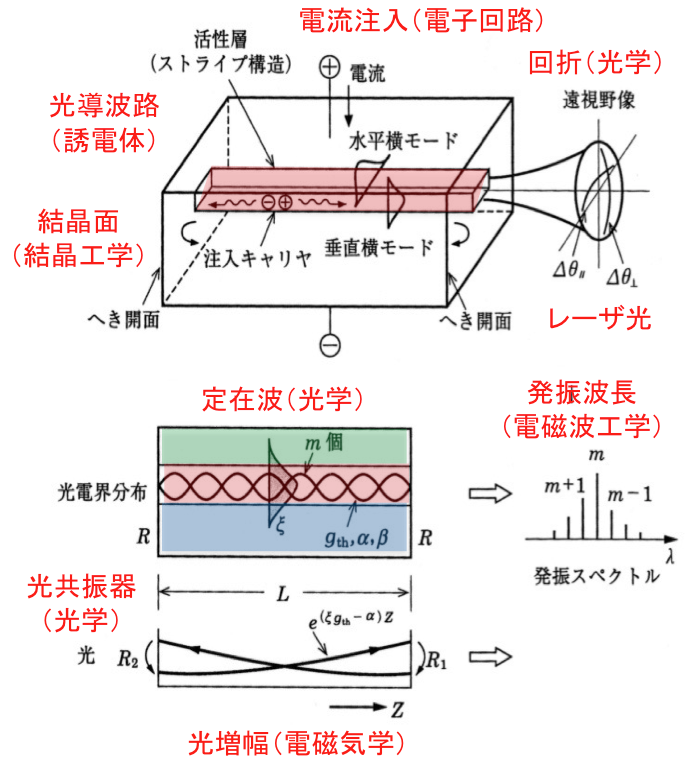
図2 半導体レーザの発振と放射
皆さんも、ぜひ学びの中で驚きやショックを受けて頂きたいと思います。きっと将来の道に繋がる出会いになることと思います。そして半導体レーザのファンが一人でも多くなることを期待しています。
機械と情報を融合するデジタルエンジニアリング
基幹理工学部 機械科学・航空宇宙学科 竹澤晃弘
近年はITや人工知能等の情報技術の著しい発達が見られます.また,コンピューターも性能が向上した上に小型化低価格化が進みました.皆さんもゲームやスマートフォンを通じこの情報科社会を楽しまれていることと思います.しかし人間は情報技術だけでは生きてはいけません.我々の生活は家電製品や車等の様々なハードウェアに支えられています.この情報技術とは一見関係のなさそうなハードウェアの開発,つまりは「ものづくり」も大きく変革しているのをご存知でしょうか.このような情報技術を活用したものづくりを「デジタルエンジニアリング」と総称します.
例えば車は事故の際に乗員を守るため,極めて高い安全性が要求されます.それはセンサーをつけたダミー人形を載せた試作車を実際に衝突させて評価しますが,昔は開発過程で何回も試作を繰り返し,膨大なコストと時間がかかっていました.今は車の衝突のような複雑な現象でも高精度なシミュレーションが可能なため,試作は最低限になっています.この技術はCAE(Computer Aided Engineering)と呼ばれます.
また,製品を設計する時,以前は本来3Dの形を2Dの図面に落とし込んで検討していましたが,今ではコンピューター上で3D-CAD(Computer Aided Design)を用いて3D形状をそのまま設計するのがあたりまえです.更には,試作程度なら3Dモデルからそのまま加工できてしまいます.(しかし正式な製品は2Dの図面を作成する場合が多いので製図の授業は依然重要です.)現代の加工機械はコンピューターによって制御されており,工具を動かす指令をプログラムすることで操作しますが,3Dデータからこのプログラムへの変換がCAM(Computer Aided Manufacturing)という技術により容易に可能であるためです.このCAD-CAM-CAEの一連の技術は,概念自体はかなり古いものの,洗練されたのは比較的最近であると感じます.
もっとシンプルなデジタルエンジニアリングツールとしては3Dプリンタがあります.小型の装置であれば数万円程度から存在し,家庭でもものづくりが楽しめるようになりましたし,高級な装置を使えば航空機でも使用可能なぐらいの強度を持つ金属部品を作成することもできます.以上の技術を活用し,短期間で高性能の製品が作り出されるようになりました.
しかしこのデジタルエンジニアリング,グローバル化が進む現代では必ずしも日本にとって良いところばかりではありません.デジタルエンジニアリング技術はものづくりの難易度を下げ,長い歴史に裏付けられた職人芸的な日本のものづくりの優位性を奪う可能性があるのです.例えば戦後日本の造船業は長い間世界一でした.しかし韓国・中国の台頭により現在では苦境に立たされており,関係企業の統廃合が進んでおります.これは安い人件費や国の支援を生かした価格攻勢をかけられたことが大きいのですが,一因として中韓がアメリカやヨーロッパ製の近代的なデジタルエンジニアリングソフトウェアを積極的に導入したこともあると言われています.(ただし,日本の造船業がデジタルエンジニアリング技術を軽視したということは全くなく,実際には1960年代という早期より開発に取り組んでいました.少し前に携帯電話業界でガラパゴス化という言葉が流行りましたが,残念ながらデジタルエンジニアリングの世界でも同じことが起こってしまったのです.)
現在は日本のお家芸である自動車産業で環境負荷を考慮し電化が推進される等,ものづくり自体が大きな転換点を迎えております.このような時こそ,経験・歴史に基づく保守的なものづくりをもう一度見直し,日本ならではの高付加価値の製品を開発していく必要があります.そのためには機械・情報といった枠組みにとらわれず,広い視点で研究・教育を行っていかなければなりません.学生の皆さんにもぜひ分野の枠を超えた広い学習意欲を期待します.
進化系統樹から進化系統ネットワークへ
基幹理工学部 応用数理学科 早水桃子
地球上には現在,数百万種以上の生物が存在するといわれていますが,これらの多様な生物たちの間にはどのような関係があるのでしょうか.17世紀頃までは,サルはヒトに進化する前段階の生物であるという考えが長らく支持され,生物の進化は単に未熟なものが成熟する一本鎖状のモデルで説明できる現象だと信じられていたようです.もちろん,この説はやがて否定され,例えばサルとヒトは両者の共通祖先から枝分かれして別々の方向に進化を遂げた産物であるという認識が定着し,生物たちがこれまでに辿ってきた進化の道筋は「系統樹」と呼ばれる木構造で広く記述されるようになりました.
しかし,一般に現実のデータにはノイズや不確かさなどが含まれているため,データが持つ情報というのは系統樹のような木構造で簡単に説明しきれるものではありません.また,系統樹は進化の道筋の分岐は表せても合流までは表現できないモデルですから,それが進化の実態に合わないという状況も多々あります.例えば植物が進化する過程では異種同士の掛け合わせで新種が出現することがありますし,微生物の世界では突然変異した細菌が自分の遺伝子を別の細菌に伝えることで病原性の低い細菌を病原性の高い細菌に進化させるという現象がよく起きます.このように,古典的な系統樹モデルだけで複雑なデータや複雑な現象を記述することには明らかに無理があるので,その拡張版モデルとして,網目のように複雑なプロセスも記述できる「系統ネットワーク」というものに期待が寄せられています(下図参照).
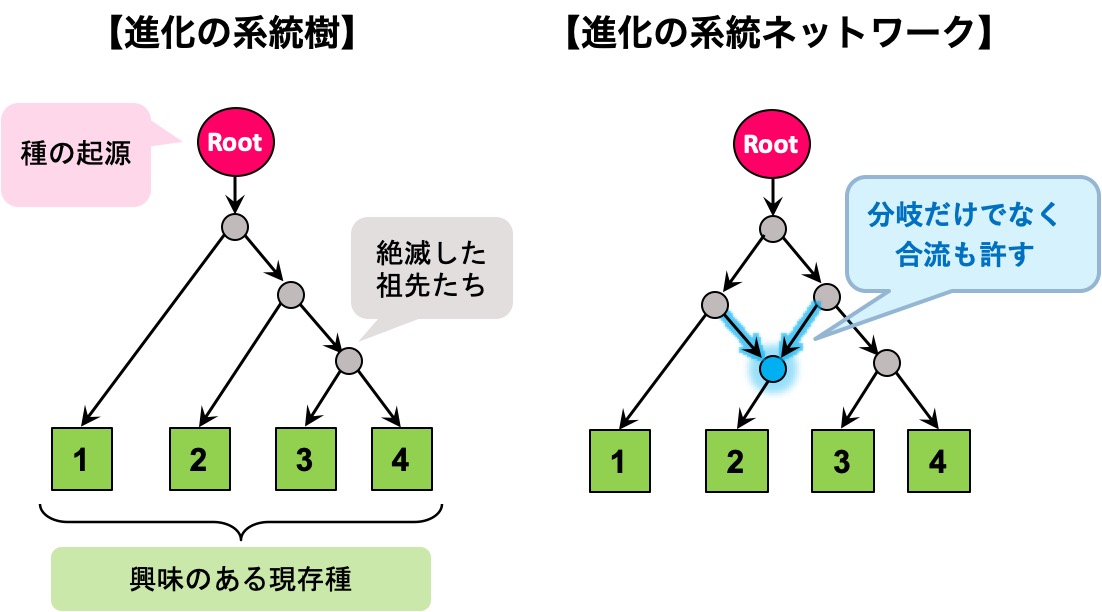
ただし,系統樹は今でも進化のスタンダードなモデルであり,系統ネットワークの登場によって過去のものになったわけではありません.確かに,進化の道筋の分岐しか表現できない系統樹に比べると,合流も分岐も表現できる系統ネットワークは柔軟で優れたモデルです.しかし,余分かもしれないものを潔く削ぎ落とした系統樹のようなモデルには,人間が解釈しやすい上に,数学的・計算機科学的にも扱いやすいという利点があります.だからこそ,系統樹の推定に関わる効率的なアルゴリズムはこれまでに数多く生まれ,生物学分野でも,それ以外の分野でも,データ解析の定番ツールとして幅広く活用されるに至りました.その反面,系統ネットワークは豊かな表現力の代償として,系統樹が備えていた単純明快さを失ってしまったのです.実際,これまでに系統樹では当たり前のようにできていたことが,系統ネットワークになった途端にハードな問題へ変貌してしまうという状況は沢山あります.そのため,この巨大で仰々しい武器を使いこなして複雑怪奇なデータから情報を見通し良く抽出するにはどうすれば良いのか,そもそもそんなことができるのか,といった疑問が山積みとなったのです.
今のところ,系統ネットワークを活用した手法のうちデータ解析の現場で広く使われているのは生物同士の非類似度を系統ネットワークで近似的に可視化するヒューリスティクスぐらいのもので,データから構築された系統ネットワークの解釈のしやすさや,信頼性の統計学的な評価方法といった多くの重要な課題が残されています.もし,それらの難題を解決して系統ネットワークを巧みに活用した新しいデータ解析技術を創ることができたなら,それは系統樹に関するデータ解析技術と同様に生物学という垣根を越えて,例えば写本系統ネットワークを構築する人文科学の研究などにもインパクトを与えるものとなるでしょう.そのフロンティアを切り拓いて人類にできることを拡げる研究には大きなやり甲斐と手応えがあります.ご興味のある方は,本稿の著者の最近の研究結果を非専門家向けに解説した下記の連載記事[1, 2]をご覧いただけたら幸いです.
[1] 早水 桃子, 進化の系統樹とデータ解析/(1)系統樹と系統ネットワークの離散数学, 日本評論社『数学セミナー』2020年1月号 通巻 699号, 数理のクロスロード
[2] 早水 桃子, 進化の系統樹とデータ解析/(2)系統ネットワークの構造定理といろいろなデータ解析への応用, 日本評論社『数学セミナー』2020年2月号 通巻 700号, 数理のクロスロード
四元数体と正の整数を4つの整数の平方和で書く問題をめぐって <基幹理工学部 数学科 成田 宏秋>
高等学校のある時点まで「\(\sf x^2+y^2\)は因数分解できない」と教わる. やがて複数平面を学習し, 「虚数単位\(\sf i\)」を手に入れると\(\sf x^2+y^2\)という2次同次式は\(\sf x^2+y^2=(x+yi)(x-yi)\)と因数分解できると教わる. この分解は, 実部をx, 虚部をyとする複素数\(\sf z=x+yi\)の複素絶対値|\(\sf z\)|(ノルムとも言う)の2乗は\(\sf |z|^2=zz ̅=x^2+y^2\)であるという話に他ならない. ここで\(\sf z ̅=x-yi\)はzの複素共役と呼ばれる.
すると自然な疑問として, 「複素数体」と呼ばれる複素数全体の集合に「第2の虚数単位j」(及びその実数倍)を付け足した数の世界「超複素数体」を与え, \(\sf {x_1}^2+{x_2}^2+{x_3}^2\)が同様に因数分解できるかという問が考えられる. 実は付け足す虚数単位が一つでは「数学的な不都合」(説明は後ほど)が生じ, そこで「第2, 第3の虚数単位j, k」(図1参照)を与えると
\(\sf {x_1}^2+{x_2}^2+{x_3}^2+{x_4}^2 \)
\(\sf =(x_1+x_2i+x_3j+x_4k)(x_1-x_2i-x_3j-x_4k)\)という分解ができる.

そこで集合{\(\sf x_1+x_2i+x_3j+x_4k | x_i \) (1≤i≤4)は実数}を考えると, これが「超複素数体」と呼ばれるにふさわしい数の集合で, 発見者の名前にちなんでHamiltonの四元数体と呼ばれる.これは乗法の可換性は失うが複素数体と同様「四則演算の構造」を持つことを注意しておく. 実は虚数単位はi, j2つだけでは四則演算を持つ集合にならず, これが「数学的不都合」の意味である. 四元数体においては\(\sf {x_1}^2+{x_2}^2+{x_3}^2=(x_1+x_2i+x_3j)(x_1-x_2i-x_3j)\)という因数分解も可能である.
ここで気分を変え, 四元数の概念の整数論の古典的事実へのちょっとした応用を試みる.
定理(Legendre) すべての正の整数は(高々)4つの整数の2乗の和で表せる.
この定理をすべての正の整数について実際に確かめることで証明するのは, 正の整数は無限にあるので原理的に不可能である. しかし現在は指定された有限個の正の整数について確かめれば, すべての正の整数について確かめたことになるという強力な定理がある.
定理“fifteen theorem”(Conway-Schneeberger, Bhargava)
正定値な「整数係数行列で表現される」2次同時多項式が1,2,3,5,6,7,10,14,15を値として取り得るなら,それはすべての正の整数を値として取り得る.
ここで「正定値」とは, 2次同時多項式がすべての変数を0とする以外のいかなる実数の代入を行っても値が正という意味である. 「整数係数行列で表現される」とは「整数係数である」よりも少し強い条件である. 例えば\(\sf {x_1}^2+{x_2}^2+{x_3}^2+{x_4}^2\)は正定値で4次の単位行列という整数係数行列で表現される2次同時多項式である. この定理は最初J. H. ConwayとW.A. Schneebergerによって与えられ当初は「1以上15以下の整数を値として取るなら成立」という主張であった. 上記の主張はフィールズ賞受賞者のM. Bhargavaが改善したものである.
ここでHamiltonの四元数体は複素数体と同様に定義されるノルム
\(\sf N(z):=zz ̅\)
\(\sf ={x_1}^2+{x_2}^2+{x_3}^2+{x_4}^2 (z=x_1+x_2i+x_3j+x_4k)\)
を持つことを注意する. ここに\(\sf : z ̅=x_1-x_2i-x_3j-x_4k \) であり複素共役の類似である. このノルムは「乗法性」と言うべき以下の性質を有する.
\(\sf N(ab)=N(a)N(b) \)
このことに注意すると上述の「fifteen theorem」の主張は, 四元数体のノルムで定義される2次同時多項式に適用すると以下の通り更に改善できる.
「1, 2, 3, 5, 7が(高々)4つの整数の平方の和で表せるのなら, それはすべての正の整数についてもそうであることを意味する.」
実際6=2×3, 10=2×5, 14=2×7, 15=3×5であるから四元数体のノルムの乗法性から上の5つの整数の場合で確認できれば十分と分かる.
 実は四元数体の乗法性を有するノルムの定義の仕方は無数にある. 私は最近の研究で四元数体の観点から同様のことが成り立つ4変数2次同時多項式の更なる例に触れ, それにより私の専攻する整数論研究が進展する機会に恵まれた. 往々にして大道具の使用を迫られる最近の整数論研究だが, 問題の起源は初等的な言葉で説明できる素朴なものであることが多い. 大道具の使用で見落としがちな初等的な視点を見逃さないよう研究に勤しみたいものである.
実は四元数体の乗法性を有するノルムの定義の仕方は無数にある. 私は最近の研究で四元数体の観点から同様のことが成り立つ4変数2次同時多項式の更なる例に触れ, それにより私の専攻する整数論研究が進展する機会に恵まれた. 往々にして大道具の使用を迫られる最近の整数論研究だが, 問題の起源は初等的な言葉で説明できる素朴なものであることが多い. 大道具の使用で見落としがちな初等的な視点を見逃さないよう研究に勤しみたいものである.
自己と他者のバウンダリー 基幹理工学部 表現工学科 渡邊克巳
私たちは、自身が他者とは異なる独立の存在であり、自分の身体、自分の感情、自分の考えが、自己に帰属しているという認識をもっています。当然のことのように感じるかもしれませんが、この感覚がどのようにして生じるのかを調べるのは、決して簡単なことではありませんでした。近年、認知科学の実験的手法を用いることで、特に、身体が自己に帰属している感覚(身体所有感)を構築する情報処理過程が明らかになりつつあります。興味深いことに、身体所有感に基づく自己と他者の境界(バウンダリー)は決して明確に線引きできるものではなく、個人の特性や他者との関係性、社会的状況等によって容易に変容されうる、柔軟かつ曖昧なものであることがわかってきました。
ラバーハンド錯視、エンフェイスメント錯視
例えば、ラバーハンド錯視という現象があります。これは、視覚的に隠された自分の手と、目の前に置かれた作り物の手が同じタイミングで繰り返し触られる(筆のようなもので撫でられる)ことにより、次第に作り物の手が自分の手であるかのような感覚が生じる現象で、1998年にMatthew Botvinick&Jonathan Cohenによって初めて報告されました。ラバーハンド錯視は、視覚情報と触覚情報の一致性によって生じると考えられています。脳はこれまでの経験をもとに、視覚情報と触覚情報が同時に知覚された場合、それは自身の身体に生じた入力であると解釈するため、作り物の手が自分の手であるように身体感覚の再構成が行われるのです。ラバーハンド錯視は自己の身体が外界に拡張する現象をよく表現していますが、より社会的な自己と他者のバウンダリー変容を表す現象として、エンフェイスメント錯視があります。エンフェイスメント錯視では、自分の顔が撫でられるのと同じタイミングで目の前の他者が撫でられるのを観察するときに生じる現象で、錯視が生じると他者の顔が自分の顔と形態的に類似していると感じるようになります。さらに、錯視の結果、他者に対してより自身に近い性格特性を帰属させることや、他人種に対するネガティブな態度がポジティブな方向に変容されたという報告もあります。このように、視覚情報と触覚情報の統合は、身体だけではなく、より高次な概念としての自己と他者のバウンダリーを接近させる(重ね合わせる)効果ももつようです。
身体内部に由来する感覚―内受容感覚―
近年、視覚や触覚のような外界から入力される感覚情報(外受容感覚)だけではなく、心臓や胃腸などの身体内部の臓器から入力される感覚情報(内受容感覚)も、身体所有感を始めとする身体的自己認識、さらには高次の概念的自己認識に重要な役割を担っていることが明らかになってきました。内受容感覚(interoception)は、イギリスの生理学者Charles Sherringtonによって1906年によって初めてその用語が用いられ、空腹やのどの渇き、尿意などに関する感覚情報を脳に伝達することで、ホメオスタシスを維持する機能を担っていると考えられています。環境の変化に応答して生体の恒常性を保つというその役割から、内受容感覚は自己身体の不変性・一貫性に関与していると考えられています。内受容感覚はその感受性の個人差が大きいことが知られていますが、内受容感覚が鋭敏な人ではラバーハンド錯視やエンフェイスメント錯視が生じにくいことや、ペリパーソナルスペース(自己身体の「周辺」と知覚される空間)が狭いという報告もあることから、内受容感覚の鋭敏さは自他のバウンダリーの強固さと関連があることが示唆されます。
このように、内受容感覚と外受容感覚の相互作用のなかで、決して固定的ではない自他の曖昧なバウンダリーが形づくられているのだと考えられます。そしてその曖昧なバウンダリーが、自他を適切に分離しつつ他者との共感を可能にするような、人間の高次の社会的認知機能において重要な役割を担っていると考えられますが、その詳細な情報処理過程は未だに不明なところが多いです。人間の社会性や他者との関係性を「身体」という側面から見ることで、認知科学研究の新たな展開が期待されます。
曲がった空間上の最適化
(基幹理工学部 情報通信学科 笠井 裕之)
近年,人工知能で着目されている機械学習技術は,あるモデルに基づきデータを用いて何かを機械的に学習する技術です.その「何か」は,そのモデルが対象とする問題に応じて様々ですが,例えば,サンプルデータの近似直線を求める問題では,その直線の傾きにあたります.ここではその「何か」を「パラメータ」と呼ぶことにしましょう.
様々な機械学習技術の中で,近年特に著しい発展を遂げているアプローチは,目的関数を定義し(先の例ではサンプルデータと直線の距離),与えられた制約条件の下でその目的関数を最小(または最大)にする「最適化問題」を定義して,パラメータ(傾き)を求解するものです.その観点で
“機械的に学習すること(機械学習) ≒ 最適化問題を解くこと”
と言うことができます.実際,Goolge社やAmazon社などがしのぎを削る機械学習分野の最難関トップ会議NeurIPSやICMLで発表される研究論文の多くは,最適化モデルや求解手法,あるいはそれらと密接に関連しています.
ところで,パラメータが探索領域Mの中で連続的に変化する連続最適化問題の求解手法は,パラメータに「制約条件」がない手法と制約条件がある手法に分けられます.前者は目的関数やその微分の情報等を用いますが,後者は制約条件も考慮するので複雑です.ところが,探索領域M自体の内在的な性質に注目すると,制約あり問題をM上の制約なし問題とみなすことができます.特にMが幾何学的に扱いやすい「リーマン多様体」のとき,その幾何学的性質を利用して,ユークリッド空間上の制約なし手法をリーマン多様体上に拡張した手法を用います.リーマン多様体とは,局所的にはユークリッド空間とみなせるような曲がった空間で,各点で距離が定義されています.また制約条件には,列直交行列や正定値対称行列,固定ランク行列など,線形代数で学ぶ行列が含まれます.このアプローチは「リーマン多様体上の最適化」と呼ばれますが,実際,この手法が対象とする問題は,前述の制約条件が現れる様々な応用に適用可能です.例えば,主成分分析等のデータ解析や,映画や書籍の推薦,医療画像解析,異常映像解析,ロボットアーム制御,量子状態推定など多彩です.深層学習における勾配情報の計算の安定性向上の手法としても注目されています.
一般に,連続最適化問題で用いられる反復勾配法は,ある初期点から開始し,現在の点から勾配情報を用いた探索方向により定まる半直線に沿って点を更新していくことで最適解に到達することを試みます.一方,リーマン多様体Mは,一般に曲がっているので,現在の点で初速度ベクトルが探索方向と一定するような「測地線」と呼ばれる曲がった直線を考えて,それに沿って点を更新します.ここで探索方向は,現在の点の接空間(接平面を一般化したもの)上で定義されます.
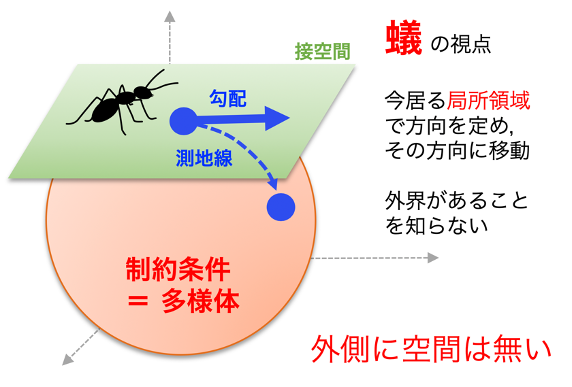
このリーマン多様体上の最適化ですが,古くは例えば1972年の論文まで遡ります.しかし,計算処理上,測地線を求めることは一般的に困難ですので,当時は広く応用されるまでには至りませんでした.当時とは比べものにならないほど計算処理能力が向上した現在においても,扱うデータ数や次元数の増加により,その問題は露わになるばかりです.しかしながら,近年,測地線を近似的に求める様々な手法が研究開発され,様々な問題で著しい成果を上げつつあります.
ところがここでの新たな問題は,ひとたび,点の移動が測地線に沿わなくなったとき,その手法が最適解に収束するかどうかの保証が無くなってしまうことです.最適化の研究では,注目している手法がいかなる初期点から開始しても収束するか,また収束する場合でも,1回の更新処理でどの程度の計算量が必要で,どの程度の更新回数で,どの程度の誤差を含む解まで到達できるか,を理論的に明らかにすることが,主要な研究対象です.さらに,その理論的結果は,その手法を搭載するシステムの設計に直接的に関係するので,応用上も極めて意義がありますし,エンジニアはそこを意識する必要があります.
現在,ユークリッド空間の手法からリーマン多様体上の手法への一般化が主流です.今後は,リーマン多様体上の手法を起源とするユークリッド空間の手法を生み出されること,またこれらの手法が様々な応用に展開されることに期待したいところです.
人間を真似する計算機
(基幹理工学部 情報理工学科 シモセラ エドガー)
昨今は人工知能ブームと言われていますが、大半の人は人工知能と聞くと合理的で冷静なロボット等を連想します。「人間は間違いを犯すが、ロボットは間違えない。」そういった考え方が多くありますが、人工知能は本当に完璧なのでしょうか?本当に人間を超えた存在なのでしょうか?それとも人間と同じように間違いを犯すのでしょうか?最近の人工知能に使われている技術を簡単に説明してから、人工知能の本当の姿に迫りたいと思います。
まず現在の人工知能に使われている技術の大半は「教師あり機械学習」という技術です。この機械学習では、まず「モデル」というものを定義し、何かしらの目標を果たすためにモデルに学習をさせます。モデルは理論上何でも近似できる方程式ですが、最初は何も出来ません。例えばモデルに写真の動物を猫か犬か区別するという目標を与えます。はじめにモデルに様々な猫の写真を見せ、これは猫だと学習させます。同様に様々な犬の写真を見せ、これは犬だと学習させます。そうして何万枚もの写真をモデルに見せることで、モデルは写真に写っている動物を猫か犬か区別出来るようになります。つまり、モデルに教師あり機械学習を行い様々な例を見せることで、モデルはやっとその例を真似し判断することが出来るようになるのです。
このようにモデルを作るのは基本的に人間です。機械学習のエンジニアは自分の経験を活かし、問題に対してこんなモデルが有効だと予想しながら設計をします。例えるなら、モデルは動物の神経回路に似ており、様々なことに対応できる構造です。しかし大きく異なるのは、自然界の動物は生まれた瞬間から自ら動き出し自主的に学習をしていきますが、モデルは学習ができるという能力を持っているにも関わらず、基本的に学習を行わないと何もできないままなのです。
次に教師あり機械学習ので重要になってくるのが、入力と出力をペアで行う訓練データです。モデルに学習させるため多量のデータが必要ですが、このデータ集めが簡単ではありません。基本的にデータのアノテーション、つまり何が正しいかどうかは人間が決めます。例えばチャットボットの学習のためにどの文章を学習に使うかは人間が決めます。先述した猫か犬か区別を学習させるために写真データを集める際に、まずこれは猫か犬か判断するのも人間です。
以上の通りに、教師あり機械学習では2つの重要な点があります。一点目、人工知能は学習させたことしか出来ません。二点目、人間が正しいと決めたデータの再現をします。つまり現在の人工知能と呼ばれている技術はあくまで限られた処理能力しか持っておらず、人間の真似しか出来ないのです。人間のように万能ではないのです。
最近人工知能の応用が増えています。アメリカでは「COMPAS」という人工知能のモデルが裁判所で再犯率を推定するために使われています。しかしその性能は、裁判の経験のない人間の能力と比べるとほぼ同じでした[1]。要するに人間の作っバイアス(偏り)のある過去のデータから学習させた人工知能モデルは、裁判の経験のない人間の能力を超えられないのです。それでもCOMPASは2000年から使われ続けています。
なぜ人間は人工知能を信じたがるのでしょうか。それは今までパソコンは基本的に間違わずに計算してきたからでしょう。。ですが人間の作ったデータを元に計算してしまうと、完璧に計算できる三角法等と異なり、人間を真似することで人間と同じ過ちを起こす可能性があるのです。現在人工知能は画像分類の分野では人間より効率的に処理を行えますが、もっとハイレベルなタスクだと人間を真似することは出来るかもしれませんが、人間を超えることはありません。本当の意味で万能なのは、人間の能力のみかもしれません。
[1]: Dressel, Julia, and Hany Farid. “The accuracy, fairness, and limits of predicting recidivism.” Science advances 4.1 (2018).
光より速く伝える
(電子物理システム学科 川西 哲也)
「ひかり」という言葉から何を思い浮かべますか?明るさでしょうか、それとも温かさでしょうか?物理学や通信工学に詳しい方ならば「速さ」を思い浮かべられる方もおいででしょう。物理的に光より速く伝わるものはありません。また、光の速さはどこの誰から見ても変わりません。これが有名なアインシュタインによる相対性理論の基本となるもので、光速不変の原理と呼ばれています。この変化することのない光の速度(光速)はどのくらい速いのでしょうか。
一秒間に地球を七周半回るスピードであるという説明は聞かれたことがあるのではないでしょうか。ほぼ30万キロメートルです。地球一周が4万キロメートルであるので、その7.5倍でちょうど30万キロメートルと、非常にきりがいい数字です。この数字のきりの良さは偶然でしょうか。答えは半分偶然で、半分は必然です。地球一周が4万キロメートルであるのは長さや重さの測定の基準となるメートル法が策定された当時の定義によります。赤道から北極までの距離を1万キロメートルとなるように取り決められたためです。地球一周はその4倍の4万キロメートルとなりますが、その7.5倍が一秒に光が進む距離であるというのは偶然です。定義された値と偶然が組み合わさって30万キロメートルがでてきます。
測定技術が進歩した結果、実際の地球は真円ではなく長さの基準に適していないことがわかってきました。現在、長さの基準は光速がもとになっています。1メートルは光が真空中で299 792 458分の1秒に進む距離と定義されています。この299 792 458は30万キロメートルをメートル換算した値にほぼ一致しています。この新しい考え方に従うと、地球一周の距離は光が1秒を7.5で割った時間の間に進む距離と言い方になります。メートル法は、国際単位系へと発展し、重さや電気量などあらゆる物理量を網羅しています。国際単位系はSI単位系ともよばれています。SIはLa Système International d’unitésの略です。メートル法がフランスで生まれたことを反映しているのでしょう。2018年にこのSI単位系は130年ぶりといわれる大改訂を受けました。これまでの電磁気学の教科書での説明を書き換える必要があるほどのものです[1]。
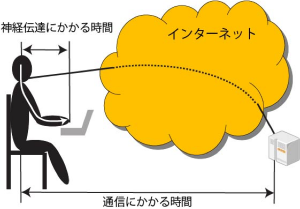
このように長さの基準にもなっている光ですが本当に速いのでしょうか?身近な情報通信機器の動作速度と比べてみましょう。最近、目にするようになったケーブルUSB3.1では10ギガビット毎秒(Gb/s)の高速データ伝送が可能です。光が地球を一周するのにかかる時間(0.133秒)の間に167MBのデータのやり取りが済んでしまいます。ゲームをやる人はフレームレートとよばれる動画を一秒に何枚表示するかという数字が気になると思います。60フレーム毎秒の場合、光が地球を一周する間に8フレーム分の遅れが発生します。つまり、地球の裏側の人とオンラインゲームをすると、いくら情報通信技術が進歩しても、相対性理論による光速不変の原理がある限り、この遅れをなくすことはできません。地球の大きさからみても光はそれほど速くないといえるでしょう。ゲームが得意な人でしたら、地球の裏側からくる光の遅さにイライラすることでしょう。宇宙の果てからくる光が我々に届くまでの時間が、宇宙誕生からの時間に匹敵することからも地球、太陽系、さらには宇宙の大きさに比べて、いかに光速が遅いかがわかると思います。
このような光が伝わることによって起きる遅れは遅延と呼ばれていて情報通信システムのいろいろな面に影響を与えています。例えば、証券取引などで高速の自動取引が使われていますが、取引所の近くにサーバーを設置しないと、大きな遅延でライバルに先を越されることになります。しかし、取引所は様々なところにあるので、これらを結ぶネットワークをいかに速くするかが課題になります。光速不変の原理は真空中の光速についての限界を示すものです。現在の大容量通信を支えているのは光ファイバです。光ファイバの屈折率は約1.5で、光速は1/1.5となり、遅延は1.5倍になってしまいます。データを光ファイバではなく、空中を飛ばす、つまり、無線技術を使えば遅延をへらすことができるはずです。マイクロ波を使ったデータ回線で商品市場のあるシカゴと金融市場のあるニューヨークを結ぶといったシステムがあります。これを使えば、光ファイバを使っている人よりも先に注文を出すことができます[2]。ただし、遅延は小さくなるものの、大量のデータを送るのには適していないという問題があります。これに対して、無線と光ファイバを組み合わせたようなシステムも提案されています[3]。普段は光ファイバを使って通信しますが、市場に大きな変化があった時に、無線信号で先回りして、発注を取り消すことができます。

光速のことを英語では”the speed of light”と呼びますが、目に見える光だけではなく、電波を含むすべての電磁波に適用できる理論です。正確にいうと電磁波の速度とよぶべきでしょう。アインシュタインはあえて”the speed of light”と名付けたのかもしれません。”speed”も”light”といった前向きで明るく、そしてわかりやすい言葉で基本原理を表したかったのでしょうか。条件によっては、ここで述べた例のように光が電波に追い越されることが起きます。このように、目的に応じて、多種多様な伝送媒体(光や電波)を組み合わせたネットワークを作っていく必要があります。今話題の第5世代携帯電話システム(5G)を使って、自動運転やロボットの制御を目指した研究がされています。このような安全にかかわるシステムでは遅延の低減が必要です。5Gではこれまでのシステムよりも低遅延のデータ通信ができるように工夫されていますが、光が伝わるために発生する遅延はどうすることもできません。この問題を解決するために、大型のデータセンタだけではなく、身近なところに小型のサーバ(エッジーサーバとよばれる)を設けて、高速性が必要な処理に関しては近いところで処理するという構成が検討されています。人間が熱いものに触れたときに大脳にまで伝えずに腕を引くいわゆる脊髄反射と同じようなメカニズムといえると思います。
最後にゲームの話に戻りたいと思います。ゲームが得意な人の指先は画面を見て瞬間的に動いているように見えます。数フレームの遅れも気になるほどの反射神経の持ち主もいるでしょう。しかし、人間の体の中を通る神経信号にも遅延があります。一般的な人間の反応速度は0.1秒程度といわれています※。つまり、指で操作する0.1秒ほど前に脳ではその指令が出ていることになります。脳から指先まで信号が伝わるのに要する時間と、光が地球をめぐるのにかかる時間がほぼ同程度であるのは偶然でしょうか。脳で発生した信号を先取りして、情報通信システムに接続することができたとすると、地球の裏側の人ともリアルタイムにやり取りができるようになるかもしれません[3]。信号が伝わる時間とそのシステムの大きさの関係を考えると、いろいろと興味深い側面が見えてきそうです。直接関係があるかどうかはわかりませんが、ゾウとネズミの時間の話を思い出しました[4]。
※一般に脳における情報処理を含んだ反応速度は0.2秒程度といわれています。ここではその半分が情報伝送に費やされていると仮定しています。
物理の基本原理をベースにして大きなシステムについて考えてみるのは楽しいです。光がもっと速ければ困ることはないのでしょうか?レーダはどんな原理で動いているんだろうかなどぜひ考えてみてください。実は光が速すぎるとレーダを作るのが難しくなってしまいます。
[1] 新SI単位と電磁気学、佐藤文隆、北野正雄、岩波書店 2018年
[2] T. Kawanishi, Transparent Waveform Transfer for Resilient and Low-latency links, IEEE Photonics Society Newsletter, pp. 4-8, August 2014
[3] T. Kawanishi, A. Kanno, Y. Yoshida and K.-I. Kitayama, Impact of wave propagation delay on latency in optical communication systems, Proc. SPIE 8646, Optical Metro Networks and Short-Haul Systems V, 86460C (5 February 2013); https://doi.org/10.1117/12.1000190
[4] ゾウの時間 ネズミの時間―サイズの生物学、本川達夫、中公新書 1992年
流体力学のカオス的性質を踏まえた宇宙の活用
(機械科学・航空学科 手塚 亜聖)
・コンピュータの計算速度の進化とともに発展したシミュレーション技術
流体力学の支配方程式として知られるNavier-Stokes方程式は,時間発展型の2階非線形偏微分方程式ですが,解析解が得られているのは,Couette流やPoiseuille流のような比較的単純な流れ場に対してのみであります.そこで,解析解を得ることが困難な問題に対して,コンピュータを用いて数値的に解くシミュレーション技術が発展しました.
流体力学の支配方程式を数値的に解く数値流体力学では,計算空間を立方体や三角錐のような形状に細かく区切り,その格子の中心や頂点に物理量を置いた計算が一般的に行われています.コンピュータの計算速度に関しては,「Mooreの法則」が有名ですが,1965年にMooreが発表した後,予測通りに指数関数的に伸び続けました.数値流体力学で扱われる格子のサイズもコンピュータの進化とともに小さくなり,より複雑な計算が可能となりました.
このようなシミュレーション技術の進歩により,初期値・境界値を適切に与えることができれば,私たちの未来を完全に予測することが可能になるのでは,と期待されますが,実際は不可能と言われています.なぜでしょうか.
・長期予報を原理的に不可能にするカオスの存在
気象学者のLorenzは,気象モデルのシミュレーションが,初期値のわずかな違いで,大きく異なることに気づきました.1963年には,Lorenz方程式と呼ばれる3変数の時間発展方程式を,気象モデルをシンプルにすることで導出して発表しています.初期値鋭敏性と言われるように,このモデルでは,初期値の微小な違いが増幅し指数関数的に誤差が拡大していきます.初期値を無限桁の精度で正確に与えることは不可能であることから,長期予報は原理的に不可能であることが示されました.
しかし,原理的に不可能というものの,シミュレーション技術の進歩による成果を活用する術を,何とかして見出したいですね.気象庁が1週間先までの天気図を予想したプロダクトとして,週間アンサンブル予想図(FEFE19)があり,気象情報を扱うWebサイトで閲覧することができます.カオス的性質を持つことから,初期値に摂動を与えたアンサンブルメンバーの数値予報を統計的に処理して作成されています.
1週間後の天気が気になる場合は,1回だけの確認で済ませずに毎日確認するのが良いでしょう.なぜなら,日を追うごとに不確かさが小さくなり,精度が上がっていくからです.
・航空運航への宇宙からのデータ活用
宇宙飛行士のように宇宙に行かない限り,宇宙から地球を見ることができませんが,映像としてなら,誰でもいつでも見ることができます.(厳密には,Webサイトに接続することが条件となりますが,本サイトを閲覧できる状況なら問題ないでしょう).2015年7月から運用を開始した気象衛星ひまわり8号では,10分に1回の頻度で全球の撮影を行っており,日本周辺域に対しては,2.5分間隔で撮影を行っています.
航空運航に不可欠な気象情報に対して,カオス的性質を持つことを考慮すると,シミュレーションによる予報値に加えて,なるべく直近の観測データを活用することが精度を高めることになります.高い高度まで発達する対流雲は,乱気流の原因の1つとして知られていますが,地上から見ると低い高度の雲に遮られる雲も,宇宙からなら容易に観測することが可能です.気象衛星による観測データをリアルタイムに近い状況で活用できるようになることで,より快適な空の旅が実現できるでしょう.